我之前出差带休假差不多两个礼拜吧,今天回北京更新一篇
我确实找到了一个有意思的东西,LivePortrait
这东西开源了,你可以认为是目前做得最好的"Sadtalker",国内也有dream-talker,EMO之类的。
我之前看EMO的效果最好,先不说EMO(它虽然标称A2V,实际上就是ASR+T2V+openpose)这种不开源,光拿git上挂个demo测不出来好坏,实际产品力有待观察,主要是LivePortrait的表情位移和精确度要吊打其他任何一个目前我看到的产品,包括EMO。
有兄弟也会说了,这Sadtalker有什么可说的,SDwebui的插件就玩过,那你错了,咱们频道从来不讲具体应用软件,也不愿意码代码,咱们还是讲的咱们老铁愿意听的东西。
讲什么呢?
就讲它发的这个论文 2407.03168 (arxiv.org)
LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control
效果还是不错的。
那具体技术有什么创新点呢?
其实有,但是都是微创新
首先模型分为两个阶段训练
第一阶段,在考虑了Diffusion路径还是其他路径之后,快手的LivePortrait团队, 没有选择市面上比较流行的Diffusion架构来做自己的模型,而是采用了GAN网络,直接从比较成熟的一个开源的paper Face-vid2vid开始做起。
face-vid2vid (nvlabs.github.io)
face-vid2vid也是很早的一个东西了,Nvidia team发的论文,Sadtalker的核心思想就是它。
为了承上启下,给没看过这块的老铁们简单讲讲这个face-vid2vid都干了啥?
简单说它就是能从一个图片s和一个给定的视频d(大多数是头部视频为主),用图片里的那个人来重生成一个能张嘴说话的视频d'
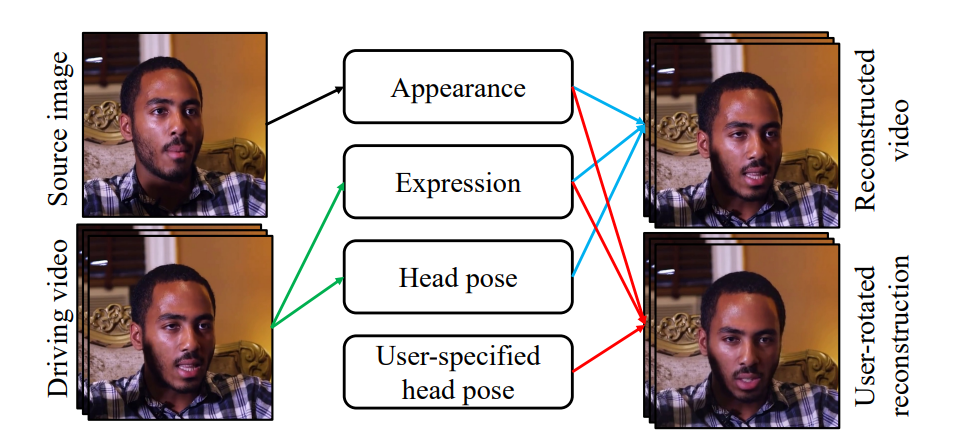
上面的图展示了face-vid2vid模型的工作流程和功能。
-
左侧:有两个输入,分别是源图像s(Source image)和驱动视频d(Driving video)。
-
中间:有四个模块,分别是外观(Appearance)、表情(Expression)、头部姿态(Head pose)和用户指定的头部姿态(User-specified head pose)。
-
右侧:有两个输出,分别是重建视频(Reconstructed video)和用户旋转后的重建视频(User-rotated reconstruction)。
工作流程上:
-
源图像s(Source image):这是模型的起始输入,提供了目标视频中主体的基本外观特征。
-
驱动视频d(Driving video):这是另一个输入,提供了模型需要模仿的表情、头部姿态等动态信息。
-
模块解释:
-
外观(Appearance):从源图像中提取的主体外观特征,用于确保合成视频中的主体外观与源图像一致。
-
表情(Expression):从驱动视频中提取的表情信息,用于在合成视频中模仿驱动视频的表情变化。
-
头部姿态(Head pose):从驱动视频中提取的头部姿态信息,用于在合成视频中模仿驱动视频中的头部运动。
-
用户指定的头部姿态(User-specified head pose):用户可以手动指定头部姿态,用于控制合成视频中的头部方向。
-
-
重建视频(Reconstructed video):将外观、表情和头部姿态结合起来,生成与驱动视频中的动态信息匹配的新视频。
-
用户旋转后的重建视频(User-rotated reconstruction):结合用户指定的头部姿态,生成特定方向上的视频。
训练的方法呢?
-
将一段视频给拆帧,每一帧的3D关键点都用序列表示,同时3D关键点表示被分解为 人物身份表示 和 运动信息表示。使用无监督学习方法学习这些3D关键点。
-
可以对 人物身份的3D关键点表示 进行3D矩阵变换,来模拟人物头部位姿的改变,比如,在生成视频时可以旋转人物的头部,侧脸旋转成正脸等。
3个任务 video reconstruction, motion transfer, face redirection。
使用 s 表示目标人物的源图像,d{d1,d2....dN}表示一段视频帧序列,d1就表示第一帧,其他的依次就是2到N,这个也很容易看明白,第一帧里面的人和图片是一样的就是s=d1,这就是个视频重建任务,如果s≠d1,那任务就是重建+动作迁移了。
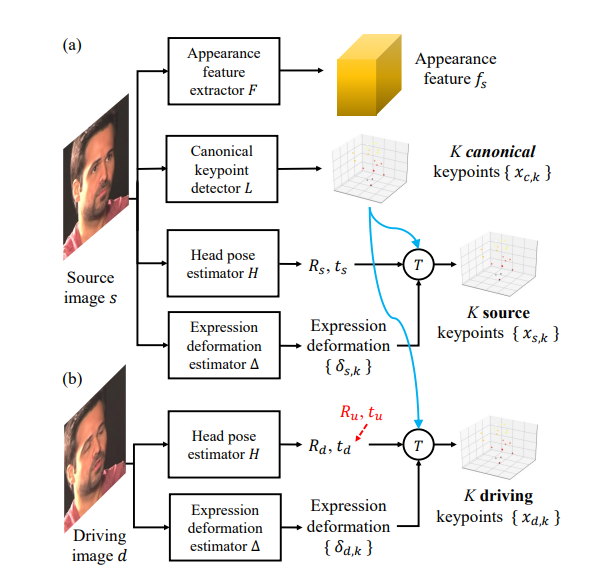
4.如上图在网络功能设计上:
-
F网络来提特征,不是静态特征,是长宽高深都包含的3D特征(fs),提取之后就允许在三维空间里面来操作了,比如转脑袋之类的。
-
L网络来提取K个3D keypoints,提取的人物中立表情下和头部姿势居中时候的特征,论文里设置为20
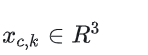
-
H网络使用两个矩阵,来表示脑袋的相对位置(Rs,ts),R是旋转矩阵,表示脑袋旋转的位移,ts是位移矩阵
![]()
![]()
-
除了以上的网络以外,又提出一个网络△,用来评估表情
![]()
-
以上的信息就可以表达为
![]()
即提取了原始图片的3D Keypoints
-
然后再提取视频那边的,因为最终还是要拿图片去deformate视频
![]()
视频就是多帧,所以没啥区别,为了区分开,用d表示视频,s表示原始图。这俩公式都一样
-
在合成的过程中,还允许手动改变 3D 头部位置。分别设置特定的Ru(旋转),Tu(平移),生成新的Rd和td
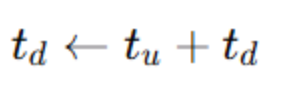

-
上图就是每一种网络提取出来的特征3D图的一个大概例子
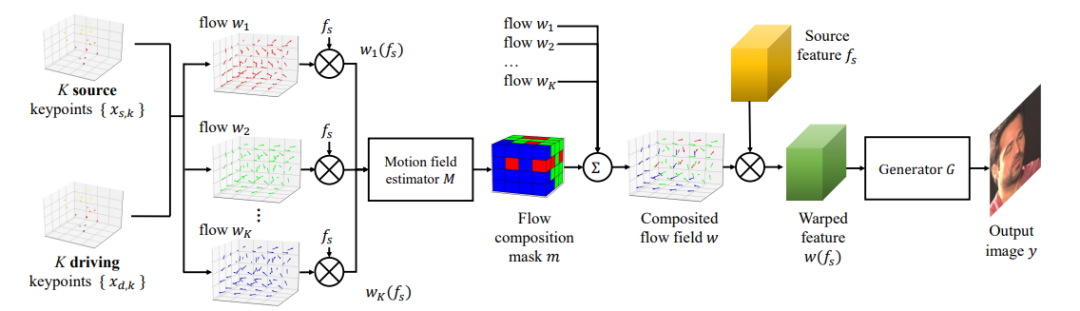
5. 视频生成的流程
我们前面讲过了怎么取Xs,k和Xd,k,如上图所示,要正式开始生成了。
-
拿这K个3D keypoints(s的和d的)都给送进网络, 每一个keypoint都引入一个一阶近似计算函数,原论文叫flow。flow的作用就是算出关于被选中的keypoint的特征fs,经过warping后的值wx(fs)。warping可以理解为对原始特征的非线性变换。
-
再把所有算完的值wx(fs)过一个mask,mask决定每个wx(fs)生成多个值里,哪个算的最好(算的不好都给mask掉就留个最好的)
-
现在就得到了每一个keypoints也就是每一个关键点的warping后的特征。
-
然后把多个warping后的特征w(fx)聚合成函数W(fs),这个聚合后的W函数,可以直接去把原始特征的s的所有keypoints的warping值计算出来,然后发送给generate G(生成器),去做生成。
这论文还挺经典的是CVPR 2021年的入围,感兴趣可以自己看一下2011.15126 (arxiv.org)
我们今天讲它只是因为它是base很重要,否则后面内容听不懂,为什么它是base呢?
刚才说了快手的LivePortrait,就采用了NV的face-vid2vid这个流派来做的延伸,创造了自己的产品和项目。
Live Portrait,分为两阶段训练
第一阶段就是找个face-vid2vid的模型来做自己的base model,但是不管是网络还是训练设计上,都做出了非常好的创新,下面我们一起来看一下我认为有提一提价值的第一阶段的创新。
1- 升级后的网络架构。快手团队将原始的canonical keypoint特征提取网络 L,头部姿态估计网络 H, 和表情变形估计网络 ∆ 统一为一个模型 M(端到端了,不用多个模型的api互调了,延迟低,但是训练难度会增加),该模型M以 ConvNeXt-V2-Tiny 作为主干,直接预测输入图像的规范关键点、头部姿态和表情变形。
使用 SPADE decoder 替代了原始的生成器(generator G),这比 face vid2vid 中的decoder更厉害。在decoder的最后层插入了一个 PixelShuffle 层,将分辨率能从 256×256 升级到 512×512。
2- 对原始的算法Xs和Xd加了缩放因子,为啥加这玩意呢?
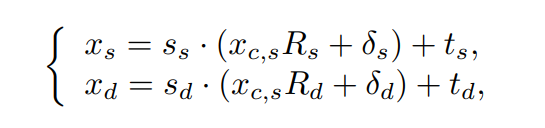
因为原始implict keypoint变换忽略了缩放因子,这往往会将缩放纳入表情变形中,从而增加训练的难度。为了解决这个问题,快手团队在运动变换中引入了一个缩放因子(别到表情那步弄了,要不太麻烦)
Ss和Sd自己管自己的缩放,Ss管图片,Sd管视频
分开比合起来好,合起来比如如下面的公式
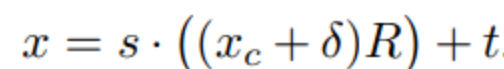
如果按上面的公式来搞,单个参数肯定比训练两个参数简单,但是,实验证明,这样会导致学习到的表情变形 δ过于灵活(因为被缩放因子给加成了),这会在驱动不同身份时引起纹理闪烁(所有闪烁基本都是cross-角色,导致生成不稳定问题,做过sd 相关animated motion类似项目的都懂)。
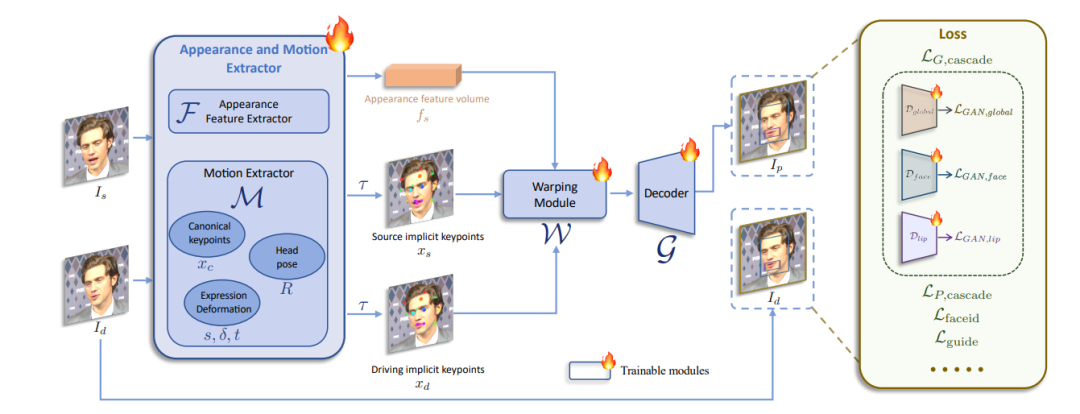
3- 新的损失函数
为了提升质量,除了face-vid2vid提供的E,L,H ,△这几个loss以外,它引入了好几个新的损失函数
在输入图像的全局区域和脸部、嘴唇的局部区域应用了感知损失和GAN损失,这些损失分别表示为级联感知损失LP,cascade和级联GAN损失LG,cascade。LG,cascade 由LGAN,global、LGAN,face和LGAN,lip 组成,这些损失依赖于相应的判别器Dglobal、Dface 和Dlip的训练(生成器和判别器就没啥可解释的了,如果不懂,可以先去学学GAN)。脸部和唇部区域通过2D语义标记点来定义。还采用了一个面部识别损失Lfaceid来保持源图像的身份一致性。
还是那句话,从我的角度上,这样肯定网络会比普通的face-vid2vid难训练很多,但是如果效果好,就有道理。
第一阶段主要就是这些网络和算法的微创新。
第二阶段是和face-vid2vid最不一样的地方。
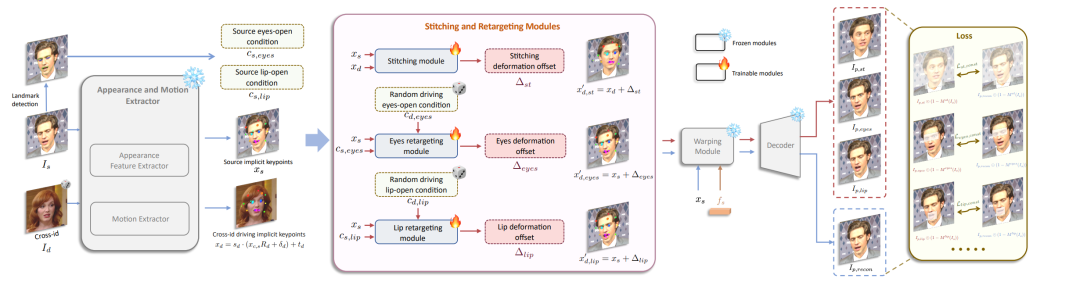
如上图所示,在第一阶段的网络基础上,冻结训练好的参数,然后在特征提取和warping函数之间,插3个模块,都是MLP,用原文的话讲就是计算量不大,但是效果特别好。
这三个模块分别是
-
Stitching module
-
Eyes retargeting
-
Lip retrargeting
不太好直译的stitchiing ,我们就叫Stitching吧,我们主要知道它是干啥的。
简单讲,就是将动态的头像能无缝重新粘贴回原始图像空间,确保没有像素错位,例如在肩部区域。这使得可以处理更大尺寸的图像并同时动画化多个面孔。(和原始图像的空间感几乎一致)
简单说一下相关的技术和算法。
在训练过程中,stitching模块S接收xs(图片,前文有,公式看糊涂了,看前文) 和xd作为输入,去评估视频的keypoint的变形偏移Δst。把Δst送入stitching网络S
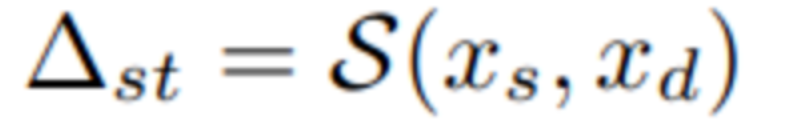
注意,第二阶段的xd的变换与第一阶段训练阶段不同,特意就使用跨身份(cross-id)而不是同一身份(same-id)的运动,以增加训练难度,旨在提高拼接的泛化能力。
然后和原来的Xd相加就得到了。
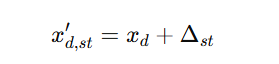
对于一个正常的图像预测
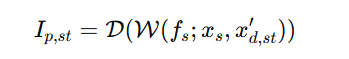
D 表示decoder,W表示Warping
然后我们把原始图像Xs也代入到这个式子,得出下式
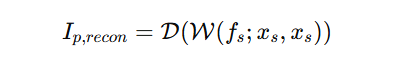
现在就可以来设计损失函数了,拼接预测图像,和用原始图像进行计算的两个I,整体损失函数计算公式如下
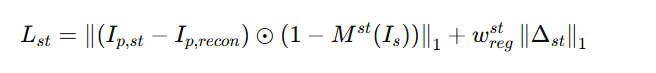
用人话来解释一下吧(我估计上面公式大多数人容易看懵)
-
训练过程:
-
用预测值减去代入原始图像的Ip,recon(self-reconstruction)的值去和1-Mst(Is)做Hadamard积。
-
Mst是个掩码矩阵,1-Mst(Is)就能把和这次计算无关的位移都掩掉
-
Wregst(实在打不出来)是一个超参
-
用这些乱七八糟的东西求L1范数,也就是曼哈顿距离
-
-
Stitching模块的作用:
-
在训练过程中用于估计驱动关键点的变形偏移,以确保合成帧中s(原图像)和d(原视频) keypoint的对齐和变形一致。
-
-
跨身份运动的使用:
-
使用跨身份(cross-id,也就是照片和视频不是一个人)而非同一身份(same-id)的运动,以增加模型训练的难度,从而提高模型在处理不同身份之间运动时的泛化能力。
-
-
损失函数的组成:
-
像素一致性损失:确保预测图像和(self-reconstruction)图像在具体部位(比如肩膀)区域的一致性。
-
L1 范数正则化:对变形偏移Δst 进行正则化,防止过度变形。
-
通过这些机制和损失函数的设计,Stitching模块能够在训练过程中有效地学习如何将源图像和视频的keypoint进行对齐和变形,从而生成高质量的视频合成效果。
另外两个模块,一个管眼睛,一个管嘴唇,我就不解释了(写不动了),其实道理都差不多,大家自己看论文去吧。
他们这个项目,重点其实就是打这三个模块,可以看一下他们的论文比较表
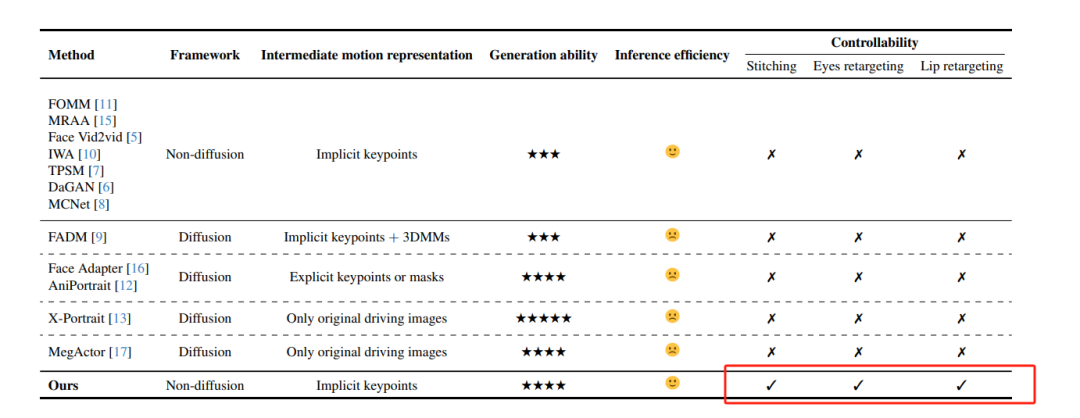
快手团队,对自己的产品也没有太多的一昧硬夸,就给了4个星的评价,但是值得注意的是,采用它是唯一四星评价的非diffusion model,和友商企鹅的Face Adapter(主要针对图片,非视频)排在一个象限。
他主要强调它与其他类似产品不一样的能力就是眼睛和嘴唇还有就是stitching这块,别的模型都不能像它一样(怎么动都能动),如果你用过别的产品比如说Sadtalker或者企鹅的FaceAdapter,你大概知道我在说什么 。
确实大多数产品,对于眼睛和嘴唇的位移不太容易像LivePortrait能做到的夸张的程度(而且好多其实是不支持video的) ,从这个点上说,快手这个不算过度宣传。
我其实本来这次休假更新就想随便写写,但是认真读了读快手的论文还是挺有意思的,所以就写多了...
我哥们有快手可灵的账号,其实我第一时间就测试过了,效果挺好的,但是说实话没达到Sora刚出来时那样特别夸张的程度
一个原因是最近如Luma还是gen-3啥的都出来了,大家都有纵向横向对比,各有长短。
二比较有意思,它有一个很大的特点,就是你prompt如果给的不够清晰,它原生出来的视频都是"老铁"化,你们可以试试

,基本能理解它的训练数据源的主力。所以就这个问题来讲,快手的多模态发展这么迅速和它本身的业务发展关系不可谓不大,有巨量的高质量的视频图文(这里高质量等于高清,数量多,多样性)
这又一次佐证了目前看来模型,算力,数据这三剑客,目前看还是数据第一重要。
从另一个层面也看出快手的这个多模态团队,确实很有能力和实力,从可灵到LivePortrait,其实都是在走微创新,而且目前看都是国内做的最好的,不是所谓第一梯队,就是最好的。确实是个很好的产品团队,不像国内有些愿意造轮子的公司(造出来的也不咋好用),也不像同样掌握着大量视频数据却啥也没做出来的公司。
快手这个是实实在在的打造产品体验的团队,值得给一个赞
其实除了让人跳舞动作控制(比如openpose),GenAI人物生成这块表情控制也是另一个难点,相当于运镜里的近景了,这块能挖的东西还有很多。当然也有两者结合做的,比如vimi,但是具体的五官效果看着就不如Liveportrait,如果Liveportrait的能力加到可灵里(做近景面部刻画,但是模型融合肯定没那么容易,可灵毕竟是Difussion,短期肯定无法端到端),再去和vimi或者sora啥的竞争,就有一定优势了,这其实是top-down和bottom-up两个路线,但是最后大家也都殊途同归了。



















